
※ 저의 풀이가 무조건적인 정답은 아닙니다.
다른 코드가 좀더 효율적이고 좋을 수 있습니다.
다른사람들의 풀이는 언제나 참고만 하시기 바랍니다.
문제 주소입니다.
https://programmers.co.kr/learn/courses/30/lessons/42747
목차
1. 문제 설명
2. 문제 해석
3. 소스 코드
3.1 주석 없는 코드
3.2 주석 있는 코드
3.3 테스트 코드
4. 결과
1. 문제 설명
|
H-Index는 과학자의 생산성과 영향력을 나타내는 지표입니다. 어느 과학자의 H-Index를 나타내는 값인 h를 구하려고 합니다. 위키백과에 따르면, H-Index는 다음과 같이 구합니다. 어떤 과학자가 발표한 논문 n편 중, h번 이상 인용된 논문이 h편 이상이고 나머지 논문이 h번 이하 인용되었다면 h가 이 과학자의 H-Index입니다. |
문제!!
|
어떤 과학자가 발표한 논문의 인용 횟수를 담은 배열 citations가 매개변수로 주어질 때, 이 과학자의 H-Index를 return 하도록 solution 함수를 작성해주세요. |
제한사항
|
예시
| citations | return |
| [3, 0, 6, 1, 5] | 3 |
| [7] | 1 |
| [0] | 0 |
| [1545, 2, 999, 790, 540, 10, 22] | 6 |
| [1, 7, 0, 1, 6, 4] | 3 |
| [10, 50, 100] | 3 |
| [4, 3, 3, 3, 3] | 3 |
| [2, 7, 5] | 2 |
| [22, 47] | 2 |
|
예제 1 : 이 과학자가 발표한 논문의 수는 5편이고, 그중 3편의 논문은 3회 이상 인용되었습니다. 그리고 나머지 2편의 논문은 3회 이하 인용되었기 때문에 이 과학자의 H-Index는 3입니다. |
2. 문제풀이
|
문제가 이해하기가 상당히 어려운 문제입니다. 이건 h회이상 인용된 논문이 h개인지 찾는 최대값 문제입니다. 따라서 인용횟수가 많은것부터 체크하여 점점 줄여가는데 i가 인용횟수보다 작아진다면 그전까지의 증가시킨 answer를 리턴시키면 됩니다. 예를 몇개 보도록하겠습니다.
[10, 50, 100] 10회 50회 100회 인용했고 논문개수는 3개입니다. 이건 인용횟수가 어쨋든 논문개수가 3개이므로 H index는 3입니다.
[4, 3, 3, 3, 3] 논문은 총 5개입니다. 하나씩 체크해 나가면 첫번째논문(4) : h-index 1; 두번째논문(3) : h index 2; 세번째논문 (3) : h index 3; 이되고 뒤에는 이보다 작은수이므로 계산하지 않습니다.
이해가 되지않으시면 따로만든 예시가 많이있습니다. 하나하나 돌려보면서 생각해보세요. |
3. 소스코드
3.1 주석없는 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
#include <vector>
#include <algorithm>
using namespace std;
int solution(vector<int> citations) {
int answer = 0;
sort(citations.begin(), citations.end(), greater<int>());
if (!citations[0]) return 0;
for (int i = 0; i < citations.size(); i++) {
if (citations[i] > i) answer++;
else break;
}
return ++answer;
}
|
3.2 주석있는 코드
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
|
#include <vector>
#include <algorithm>
using namespace std;
int solution(vector<int> citations) {
int answer = 0;
sort(citations.begin(), citations.end(), greater<int>());
//제일 큰값이 0이라면 H-index 는 0이다
if (!citations[0]) return 0;
for (int i = 0; i < citations.size(); i++) {
//h-index범위 안이라면
if (citations[i] > i) answer++;
//최대값을 벗어났다면
else break;
}
return ++answer;
}
|
3.3 테스트 코드 추가
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
|
#include <string>
#include <vector>
#include <algorithm>
#include <iostream>
using namespace std;
int solution(vector<int> citations) {
int answer = 0;
sort(citations.begin(), citations.end(), greater<int>());
//제일 큰값이 0이라면 H-index 는 0이다
if (!citations[0]) return 0;
for (int i = 0; i < citations.size(); i++) {
//h-index범위 안이라면
if (citations[i] > i) answer++;
//최대값을 벗어났다면
else break;
}
return ++answer;
}
void print(vector<int> citations, int answer) {
int t = solution(citations);
if (t == answer)
cout << "정답" << endl;
else
cout << "틀림" << endl;
}
int main(){
print({ 3, 0, 6, 1, 5 }, 3);
print({ 7 },1);
print({ 1545, 2, 999, 790, 540, 10, 22 }, 6);
print({22, 47}, 2);
print({2, 7, 5}, 2);
print({4, 3, 3, 3, 3}, 3);
print({10, 50, 100}, 3);
print({1, 7, 0, 1, 6, 4}, 3);
print({0}, 0);
return 0;
}
|
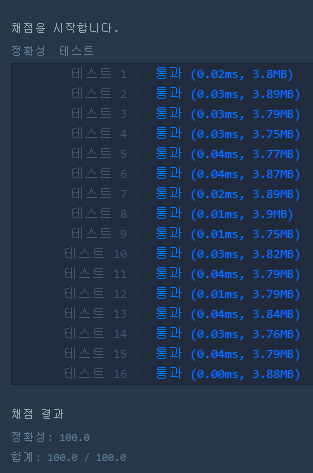
4. 결과
'코딩테스트 > 프로그래머스' 카테고리의 다른 글
| 짝지어 제거하기 C++(팁스다운2017)[프로그래머스] (1) | 2019.11.29 |
|---|---|
| 모의고사 C++(완전탐색)[프로그래머스] (0) | 2019.11.27 |
| 가장 큰 수 C++ (정렬)[프로그래머스] (3) | 2019.11.21 |
| K 번째 수 C++(정렬)[프로그래머스] (0) | 2019.11.20 |
| 이중우선순위 큐 C++(힙)[프로그래머스] (0) | 2019.11.19 |
댓글